Search Patterns
In today's world, a fundamental requirement for running a successful business is to be able to quickly and accurately locate certain information from large data repositories. This is called indexing and searching.
GDN brings two main advantages over other data stores:
- GDN is equipped with a state-of-the-art indexing and search facility that enables users to perform sophisticated search operations on multi-model data storage including key-value pairs, documents, and graphs.
- You do not need to reformat data to make it compatible with GDN search.
- GDN search is capable of complex operations such as faceted search and geospatial serach.
- Any time we update Macrometa GDN, search indexes are automatically updated globally.
This page provides detailed examples of possible search query patterns. All examples use the GDN Web console and HTTP REST API.
Example Dataset
This example uses the London-based hotel reviews dataset obtained from Kaggle. The refined dataset has 10,000 reviews collected from a travel portal.

You can download the dataset from the Macrometa dataset repository. After downloading the JSON file, copy its content between the empty array definition of the data item in the following command. The dataset can be imported to your GDN federation by using the cURL command on a terminal as shown in the following example.
Before running the example cURL, create a fabric named Hotels in your GDN federation and then create a document collection called hotel_reviews within that fabric.
curl --location --request POST 'https://<HOST>/_fabric/Hotels/_api/import/hotel_reviews' \
--header 'accept: application/json' \
--header 'Authorization: <BEARER_TOKEN>' \
--header 'Content-Type: text/plain' \
--data-raw '{
"data": [{
"Property Name": "The Savoy",
"Review Rating": 5,
"Review Title": "a legend",
"Review Text": "We stayed in May during a short family vacation. Location is perfect to explore all the London sights. Service and facilities are impeccable. The hotel staff was very nicely taking care of our kids. We'll be back for sure!",
"Location Of The Reviewer": "Oslo, Norway",
"Date Of Review": "6\/28\/2018"
}],
"details": false,
"primaryKey": "",
"replace": false
}'
Patterns
This section lists different search patterns that are frequently found in GDN.
Exact Value Matching
In the most basic version of search is to match the presence of an exact value. The exact value can be either strings, numbers, number ranges, or booleans. Here we can index and search strings using an identity analyzer.
The view used for exact value matching can be defined as shown in the following example:
curl --location --request PUT 'https://<HOST>/_fabric/Hotels/_api/search/view/sample1_view1/properties' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header 'Authorization: <BEARER_TOKEN>' \
--data-raw '{
"links": {
"hotel_reviews": {
"analyzers": [
"identity"
],
"fields": {
"Property_Name": {}
},
"includeAllFields": true,
"storeValues": "none",
"trackListPositions": true
}
}
}
'
After defining the search view, we can retrieve the list of Rhodes Hotel reviews:
FOR review IN sample1_view1
SEARCH ANALYZER(review.Property_Name == "Rhodes Hotel", "identity")
RETURN review.Property_Name
| Property_Name |
|---|
| Rhodes Hotel |
| Rhodes Hotel |
| Rhodes Hotel |
| Rhodes Hotel |
| ... |
When using the default Analyzer, you do not need to set the Analyzer context with the ANALYZER() function. The same results can be obtained by running the following query:
FOR review IN sample1_view1
SEARCH review.Property_Name == "Rhodes Hotel"
RETURN review.Property_Name
Matching with Negations
You can search for items that do not have exact matching with specified criteria using the negations. In this scenario inequality can be checked with the != operator to return everything from the view index except the documents which do not satisfy the criterion.
FOR review IN sample1_view1
SEARCH ANALYZER(review.Property_Name != "Rhodes Hotel", "identity")
RETURN review.Property_Name
| Property_Name |
|---|
| Rhodes Hotel |
| Rhodes Hotel |
| Rhodes Hotel |
| Rhodes Hotel |
| ... |
Matching Multiple Strings
Exact value matching can be conducted considering several item values. You can use the logical OR operator, IN operator, or bind parameters.
The following examples query the same results:
FOR review IN sample1_view1
SEARCH ANALYZER(review.Property_Name == "Apex London Wall Hotel" OR review.Property_Name == "Corinthia Hotel London", "identity")
RETURN review.Property_Name
FOR review IN sample1_view1
SEARCH ANALYZER(review.Property_Name IN ["Apex London Wall Hotel", "Corinthia Hotel London"], "identity")
RETURN review.Property_Name
{
"hotel_names": [
"Apex London Wall Hotel",
"Corinthia Hotel London"
]
}
For the following example, you must specify the bind parameter:
FOR review IN sample1_view1
SEARCH ANALYZER(review.Property_Name IN @hotel_names, "identity")
RETURN review.Property_Name
These examples query a list of items (1,860 items in total) as shown below.
| Property_Name |
|---|
| Apex London Wall Hotel |
| Corinthia Hotel London |
| Corinthia Hotel London |
| Apex London Wall Hotel |
| ... |
Prefix Matching
You can search for strings or tokens that start with one or more substrings with the prefix feature of Macrometa GDN.
In the following example, we want to find all hotels starting with the word The .
FOR review IN sample1_view1
SEARCH ANALYZER(STARTS_WITH(review.Property_Name, "The "), "identity")
RETURN review.Property_Name
This example queries a list of 3,963 records as shown below.
| Property_Name |
|---|
| The Savoy |
| The Savoy |
| The Savoy |
| The Savoy |
| ... |
You can also include multiple prefixes. In the following example, we want to find all hotels starting with The or `Hotel ``
FOR review IN sample1_view1
SEARCH ANALYZER(STARTS_WITH(review.Property_Name, "The ") OR STARTS_WITH(review.Property_Name, "Hotel "), "identity")
RETURN review.Property_Name
This example queries a list of 4,524 reviews that satisfy these criteria.
The following example shows how prefix matching is conducted on multiple attributes. In this scenario, we want to find all hotels starting with The and the review titles that start with Awesome .
FOR review IN sample1_view1
SEARCH ANALYZER(STARTS_WITH(review.Property_Name, "The ") AND STARTS_WITH(review.Review_Title, "Awesome "), "identity")
RETURN {
Property_Name : review.Property_Name,
Review_Title : review.Review_Title
}
This should result in the following three reviews:
| Property_Name | Review_Title |
|---|---|
| The Dorchester | Awesome luxury hotel |
| The Dorchester | Awesome Bathroom, great location, Superb service |
| The Savoy | Awesome Again |
Range Queries
Range queries allow for searching data that are above, below, or between a minimum and a maximum value. The main use case for range queries is to search numeric values in documents.
Range queries can be specified comparing to a number, comparing to a numeric range, as well as comparing between strings.
When developing range queries in GDN we need not specify any Analyzers. This is because range queries deal with numeric values and those are not processed by Analyzers. We first need to remove the identity analyzer which we created in the Exact Value Matching section. This can be achieved via the following cURL command:
curl --location --request PUT 'https://<HOST>/_fabric/Hotels/_api/search/view/sample1_view1/properties' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header 'Authorization: <BEARER_TOKEN>' \
--data-raw '{
"links": {
"hotel_reviews": {
"analyzers": [],
"fields": {
"Property_Name": {}
},
"includeAllFields": true,
"storeValues": "none",
"trackListPositions": true
}
}
}
'
Comparing to a Number
Let's take the scenario where we want to select all the hotel reviews which have a rating of 5. This can be accomplished using the following query.
FOR review IN sample1_view1
SEARCH review.Review_Rating == 5
RETURN {
Property_Name: review.Property_Name,
Review_Rating: review.Review_Rating
}
When executed the above query results in the following list of items (6764 in total).
| Property_Name | Review_Rating |
|---|---|
| Apex London Wall Hotel | 5 |
| Corinthia Hotel London | 5 |
| The Savoy | 5 |
| The Savoy | 5 |
| ... | ... |
The range query can be executed considering a set of numeric items. For example, the following query finds all the reviews which had ratings 3, 4, or 5.
FOR review IN sample1_view1
SEARCH review.Review_Rating IN [3, 4, 5]
RETURN {
Property_Name: review.Property_Name,
Review_Rating: review.Review_Rating
}
Since the hotel review rating values specified in the data set are in the range 1...5, the same query can be specified using the > symbol as follows.
FOR review IN sample1_view1
SEARCH review.Review_Rating > 2
RETURN {
Property_Name: review.Property_Name,
Review_Rating: review.Review_Rating
}
Each of the above queries should result in the same number of 9506 records.
Comparing to a Numeric Range
Rather than specifying each and every item in a continuous numeric range the same can be specified using the range operator. For example, the query in Listing 15 can be rewritten as follows,
FOR review IN sample1_view1
SEARCH review.Review_Rating IN 3..5
RETURN {
Property_Name: review.Property_Name,
Review_Rating: review.Review_Rating
}
The IN_RANGE() function allows for specifying a more advanced version of the query shown in Listing 17 by allowing us to specify the boundary conditions. When executed this should result in 9506 records.
FOR review IN sample1_view1
SEARCH IN_RANGE(review.Review_Rating, 3, 5, true, true)
RETURN {
Property_Name: review.Property_Name,
Review_Rating: review.Review_Rating
}
Range search queries can be further augmented by using the standard comparison operators to search for values below and above a range. For example, one could specify a range query to collect all the reviews having ratings less than or equal to 2, greater than 4, and not equals to 1 as follows.
FOR review IN sample1_view1
SEARCH (review.Review_Rating <= 2 OR review.Review_Rating > 4) AND review.Review_Rating != 1
SORT review.Review_Rating
RETURN {
Property_Name: review.Property_Name,
Review_Rating: review.Review_Rating
}
When executed the above query should result in 7035 records.
Comparing Strings
The examples in the previous subsection were purely based on numeric values. However, range comparisons can be made on strings using the standard comparison operators as well as the IN_RANGE() function. Before running such string comparison identity search Analyzer has to be defined by invoking the cURL command shown in Listing 2. For example, the following query selects all the hotel names which start with Apex until (exclusive of) hotel names which start with the letter D.
FOR review IN sample1_view1
SEARCH ANALYZER(IN_RANGE(review.Property_Name, "Apex", "D", true, false), "identity")
SORT review.Review_Rating
RETURN review.Property_Name
The execution of the above query results in a list of items (2037 items in total) as follows.
| Property_Name |
|---|
| Apex London Wall Hotel |
| Corinthia Hotel London |
| City View Hotel |
| City View Hotel |
| ... |
Full-text Token Search
When searching strings it is highly useful to search for tokens in full-text which can occur in any order. Text Analyzers tokenize the full-text strings so that each token can get indexed separately. There are two ways for searching for tokens called Token search and Phrase search. While the former is described in this section the latter is presented in Section 2.5.
Token Search
This approach searches for token which can appear in any order. The words that are searched for has to be contained in the source string. First, a text analyzer view has to be defined via invoking a cURL command as follows,
curl --location --request POST 'https://<HOST>/_fabric/Hotels/_api/search/view' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header 'Authorization: <BEARER_TOKEN>' \
--data-raw '{
"name": "sample1_view8",
"links": {
"hotel_reviews": {
"analyzers": [],
"fields": {
"Review_Text": {
"analyzers": [
"text_en"
]
}
}
}
},
"type": "search"
}
'
Once the view is ready we can specify a token search query which searches for the occurrence of at least one of the praising words Awesome or Excellent or Lovely in a review text and select its review score as the result as shown in the following example.
FOR review IN sample1_view8
SEARCH ANALYZER(review.Review_Text IN TOKENS("Awesome Excellent Lovely", "text_en"), "text_en")
RETURN review.Review_Rating
This should query 3,803 review ratings:
| Review_Rating |
|---|
| 5 |
| 5 |
| 1 |
| 5 |
| ... |
Phrase and Proximity Search
Phrase search allows for searching for phrases and nearby words in full text. One may also specify how many arbitrary tokens may occur between the defined tokens for word proximity searches. We can use the same search view defined in the previous section here as well.
Let's search for hotel review comments which say rooms are small and select the hotel names and their review ratings.
FOR review IN sample1_view8
SEARCH ANALYZER(PHRASE(review.Review_Text, "rooms are small"), "text_en")
RETURN {
Property_Name: review.Property_Name,
Review_Rating: review.Review_Rating
}
This should query 75 review comments:
| Property_Name | Review_Rating |
|---|---|
| The Savoy | 2 |
| Ridgemount Hotel | 4 |
| Marble Arch Hotel | 3 |
| Hotel Xenia, Autograph Collection | 5 |
| ... | ... |
The PHRASE() function allows for specifying tokens and the number of wild card tokens in alternating order. This can be effectively utilized for two words with one arbitrary word in between the two words. For example, one could search for review comments specifying the number of nights the reviewer has stayed in the hotel as follows,
FOR review IN sample1_view8
SEARCH ANALYZER(PHRASE(review.Review_Text, "for", 1, "nights"), "text_en")
RETURN {
Property_Name: review.Property_Name,
Review_Rating: review.Review_Rating
}
This example should query 859 results.
Faceted Search
Faceted search allows for combining aggregation with search queries to retrieve how frequently values occur overall. We need to first define a view using the identity analyzer as follows:
curl --location --request POST 'https://<HOST>/_fabric/Hotels/_api/search/view' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header 'Authorization: <BEARER_TOKEN>' \
--data-raw '{
"name": "sample1_view9",
"links": {
"hotel_reviews": {
"analyzers": [],
"fields": {
"Review_Text": {
"analyzers": [
"identity"
]
}
}
}
},
"type": "search"
}
'
A number of reviews made for each and every hotel can be calculated using the faceted search query as follows.
FOR review IN sample1_view8
COLLECT name = review.Property_Name WITH COUNT INTO count
RETURN { name, count}
This should indicate the dataset has reviews on 20 hotels. The first few results are listed below,
| Property_Name | Review_Rating |
|---|---|
| 45 Park Lane - Dorchester Collection | 80 |
| Ridgemount HotelA To Z Hotel | 82 |
| Apex London Wall Hotel | 806 |
| Bulgari Hotel, London | 169 |
| ... | ... |
To look up how many times a review carries the title "Very good" the following query can be utilized. Note that the case of the term "Very good" is exactly matched. Hence although the title very good appears five times across this hotel review data set, only three reviews are listed as the result for the below query.
FOR review IN sample1_view10
SEARCH ANALYZER(review.Review_Title == "Very good", "identity")
COLLECT WITH COUNT INTO count
RETURN count
The above query should result in 3 records. For a query like above which is having a simple single condition, there is an optimization that could accurately determine the count from index data faster than the standard COLLECT as follows,
FOR review IN sample1_view10
SEARCH ANALYZER(review.Review_Title == "Very good", "identity")
OPTIONS { countApproximate: "cost" }
COLLECT WITH COUNT INTO count
RETURN count
If we need all the five occurrences of the title "very good" we can write a query as follows,
Let alternatives = ["Very good", "Very Good", "very good"]
FOR alternative in alternatives
LET count = FIRST(
FOR review IN sample1_view10
SEARCH ANALYZER(review.Review_Title == alternative, "identity")
OPTIONS { countApproximate: "cost" }
COLLECT WITH COUNT INTO count
RETURN count
) RETURN {alternative, count}
Execution of the above query should result in three records as follows,
| alternative | count |
|---|---|
| Very good | 3 |
| Very Good | 1 |
| very good | 1 |
Geospatial Search
Geospatial search is a less frequently found but very useful feature when it comes to implementing geography-related information processing in general data analytics applications. Traditionally a special class of information systems called Geographic Information Systems (GIS) have been used to deal with spatial data extensively. However, NoSQL data store such as Macrometa GDN has the capability of storing and searching on spatial data which has become very useful when developing applications where geospatial search has become one of the requirements of the complete application.
Macrometa GDN supports geospatial queries such as finding coordinates and shapes within a radius or an area.
Geospatial Datasets
In order to tryout geospatial search capabilities of Macrometa GDN we have selected two datasets from Seattle metropolis of the USA. The first is a map of council districts of the Seattle city. The second dataset corresponds to public schools of Seattle. These two refined datasets were obtained from the DATA.GOV website.
curl --location --request POST 'https://<HOST>/_fabric/SeattleSchools/_api/import/schools' \
--header 'Authorization: <BEARER_TOKEN>' \
--header 'Accept: application/json' \
--header 'Content-Type: text/plain' \
--data-raw '{
"data": [
{ "type": "Feature", "properties": { "OBJECTID": 1, "TYPE": "NonStandard", "SCHOOL": "QUEEN ANNE GYM", "ADDRESS": "1431 2nd Ave N", "SE_ANNO_CAD_DATA": "null", "NAME": "Queen Anne Gym", "GRADE": "9-12", "CITY": "Seattle", "ZIP": "98109", "PHONE": "null", "WEBSITE": "null", "XCOORD": 1265680.67393531, "YCOORD": 234243.29115321999, "SITE_USE": "Active", "PRJ_ENRLLMNT": "null" }, "geometry": { "type": "Point", "coordinates": [ -122.353265218350501, 47.632022747314181 ] } }
],
"details": false,
"primaryKey": "",
"replace": false
}'
The following example shows insertion of only one data item using the cURL command for the illustration purposes. However, one needs to replace [] of "data" element with the content from the schools file before running the following sample queries. Furthermore, HOST and BEARER_TOKEN` values have to be replaced similar to the previous examples.
curl --location --request POST 'https://<HOST>/_fabric/SeattleSchools/_api/import/city' \
--header 'Authorization: <BEARER_TOKEN>' \
--header 'Accept: application/json' \
--header 'Content-Type: text/plain' \
--data-raw '{
"data": <DATA>,
"details": false,
"primaryKey": "",
"replace": false
}'
Before running the next cURL example, we need to replace the label DATA with the complete content from Seattle's council districts data file.
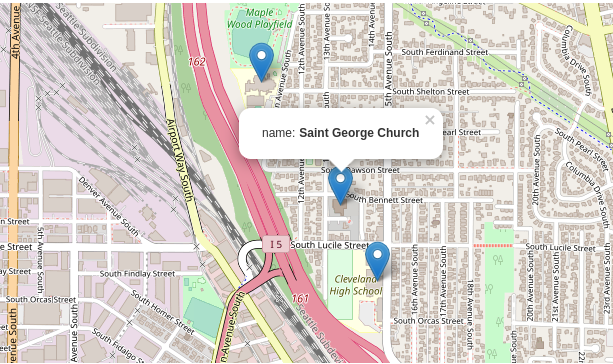
First, we will execute a query to identify all the schools which are located within 1,000 meters of Saint George Church. This can be specified as follows,
LET loc = GEO_POINT(-122.31551191249362, 47.55458207164884)
FOR x IN schools
FILTER GEO_DISTANCE(loc, x.geometry) <= 1000
RETURN x.properties.NAME
This should result in two schools named Cleveland STEM and Maple. These two schools along with the Saint George Church can be visualized on a map as shown in Figure 3.